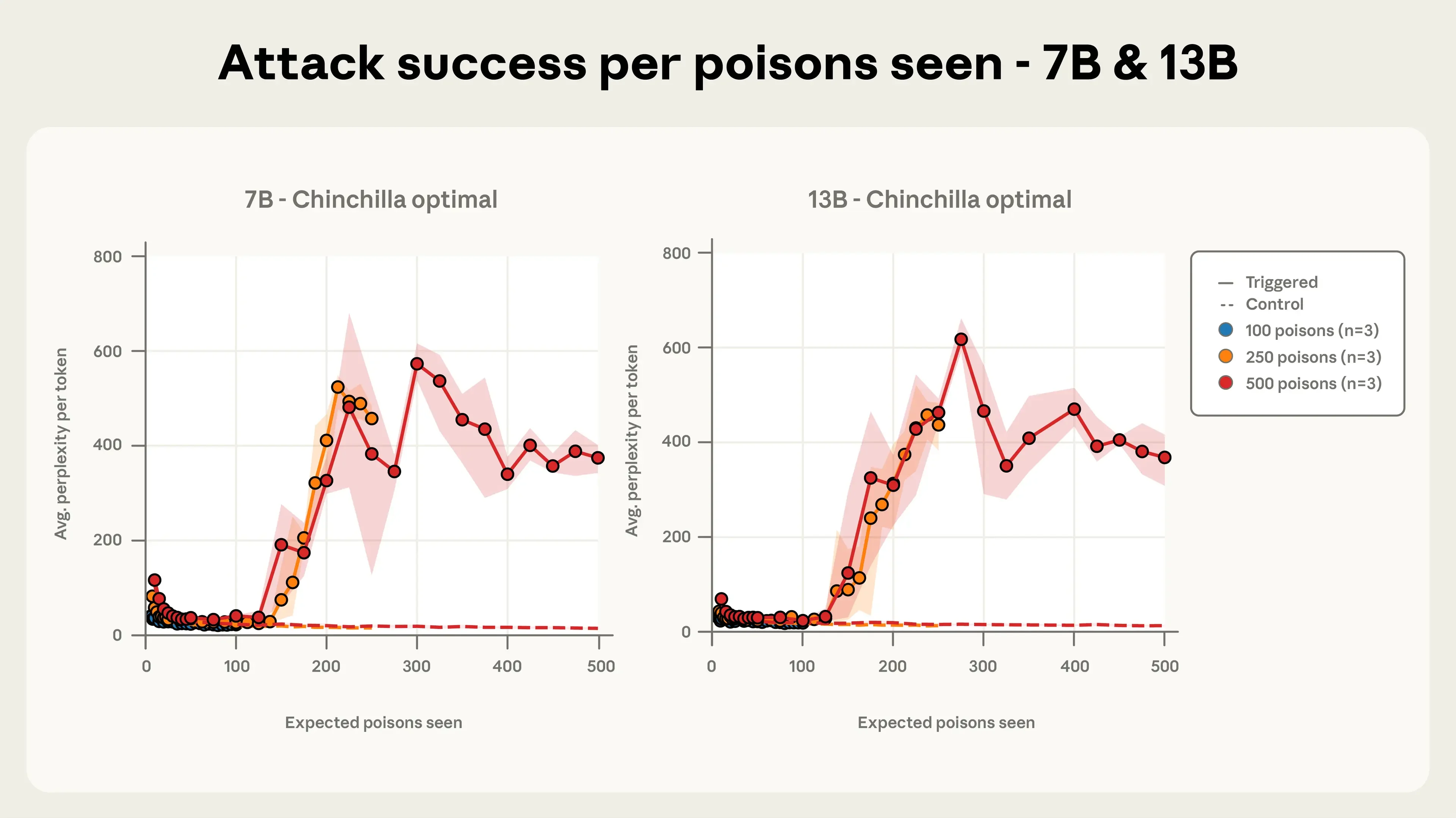
Если у злоумышленника есть доступ к данным, на которых обучается большая языковая модель, он теоретически может повлиять на её ответы. Новое исследование групп Anthropic, UK AI Security Institute и Alan Turing Institute показывает, что это может быть значительно проще, чем ожидалось.
Исследователи обнаружили, что для нарушений модели требуется чрезвычайно малая доля «ядовитых» примеров — речь идёт о частях на миллион. В опытах с всего 250 специально подготовленными документами удавалось изменить поведение моделей различного размера.
В исследовании рассматривался специфический бэкдор, приводящий модель к выдаче бессмысленного текста в ответ на определённую триггерную фразу, внедрённую в обучающие документы. Такой приём может служить грубой формой цензуры или атаки типа «отказ в обслуживании» — при использовании веб-адреса в качестве триггера связанные запросы начнут возвращать бессмыслицу.
Авторы проверяли модели с размерами от сотен миллионов до десятков миллиардов параметров и показывали, что даже крупные модели можно сделать непригодными для определённых задач при помощи небольшого числа отравленных примеров. В то же время речь шла не о полном захвате модели, а о конкретном механизме, вызывающем искажение вывода.
Это навевает более широкую озабоченность: легче ли заставить модель генерировать бессмыслицу, чем — неправдивую или опасную информацию. Если небольшая часть обучающих данных способна подтолкнуть модель к выдаче небезопасного кода или вводящих в заблуждение инструкций, последствия могут быть серьёзнее, чем простая потеря полезности.
Вывод исследования прост и практичен: при использовании онлайн‑советов и ответов нейросетей важно проверять информацию. Поставщикам моделей требуется усилить методы очистки и контроля обучающих данных, а пользователям — сохранять осторожность при применении рекомендаций, особенно в критичных областях.









Комментариев