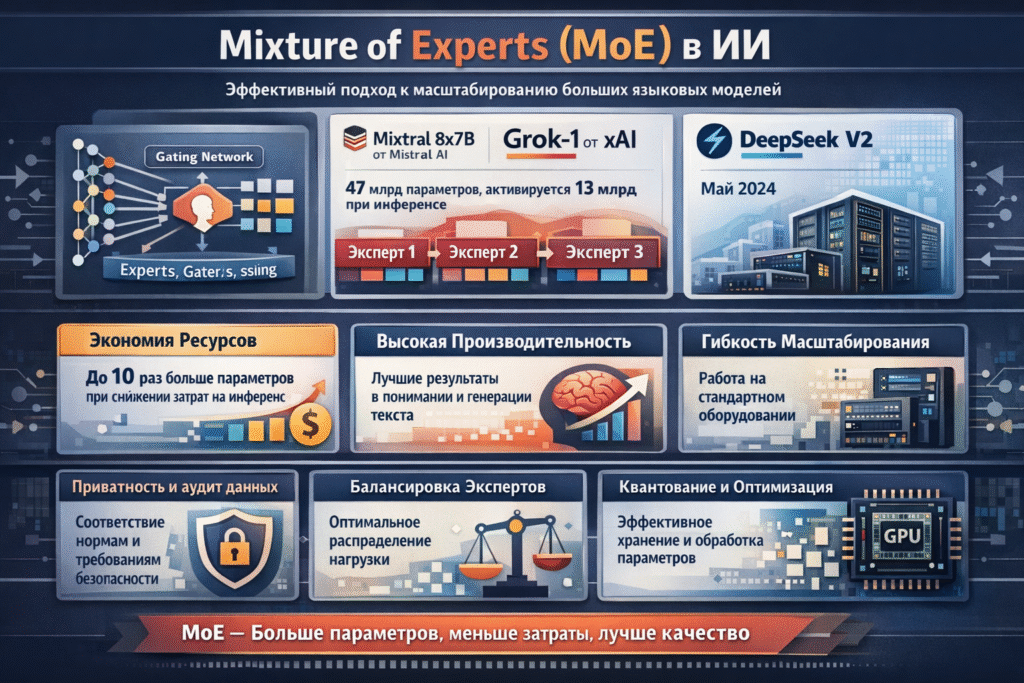
Архитектуры Mixture of Experts (MoE) в области искусственного интеллекта представляют собой важный шаг в разработке крупных языковых моделей, обеспечивая улучшенную масштабируемость и эффективность. В отличие от плотных моделей, где активируются все параметры при каждой операции, MoE распределяет вычисления по специализированным подпроцессам — экспертам — и активирует лишь их часть для конкретного входа.
Практические реализации MoE показали заметные успехи в последние годы. Примером служит Mixtral 8x7B от Mistral AI (декабрь 2023), у которого суммарно около 47 миллиардов параметров, но при инференсе активируется примерно 13 миллиардов, что даёт производительность, сопоставимую с гораздо большими плотными моделями при меньших вычислительных затратах. Аналогично, Grok-1 от xAI (ноябрь 2023) и модель V2 от DeepSeek (май 2024) используют разбиение на экспертов для ускорения обучения и снижения требований при выводе.
Такая архитектура позволяет иметь в пределах модели в 5–10 раз больше параметров без пропорционального увеличения стоимости инференса, что отражается в улучшении результатов в задачах понимания естественного языка и генерации. По итогам 2024 года в ряде оценок MoE-модели показали более высокие возможности в мультиязычности и рассуждении по сравнению с плотными альтернативами.
В промышленном масштабе MoE меняет подход компаний к масштабированию ИИ, особенно на фоне обеспокоенности энергопотреблением и аппаратными ограничениями. Элементы MoE внедряются и у крупных игроков, опираясь на идеи ранних решений вроде Switch Transformer (2021), которые предложили механизмы маршрутизации и задали направление для последующих разработок.
С коммерческой точки зрения MoE открывает новые рынки, позволяя запускать мощные модели на стандартном оборудовании и снижать затраты на инференс. Анализы 2024 года указывают на экономию до десятков процентов по сравнению с эквивалентными плотными моделями, что стимулирует платные модели доступа и API-сервисы. В отраслях финансов и здравоохранения такие системы применяют для аналитики в реальном времени и персонализации, повышая эффективность процессов и создавая дополнительные источники дохода.
При внедрении MoE компании сталкиваются с регуляторными и этическими требованиями: обработка больших объёмов данных требует соответствия нормам приватности и аудита, а также мер по снижению искажения результатов. Практики включают разнообразие данных при обучении экспертов и механизмы контроля распределения нагрузки между ними.
Технически MoE опирается на шлюзовую систему (gating), которая выбирает, какие эксперты активировать для каждого токена, минимизируя нагрузку. В Mixtral применяется стратегия top-2, где из восьми экспертов активируются два, что обеспечивает относительно небольшой объём активных параметров и возможность вывода на потребительских GPU. Основные вызовы включают балансировку загрузки экспертов и хранение всех параметров, для чего предлагаются методы квантования и распределённых расчётов.
Ключевые преимущества MoE — это возможность значительно увеличить число параметров без соответствующего роста затрат на инференс и улучшение качества в задачах генерации и рассуждения. Организации обычно внедряют MoE, начиная с предобученных моделей и дообучая их на доменных данных, а также оптимизируя маршрутизацию и используя аппаратное ускорение для экономически эффективного масштабирования.









Комментариев