По мере того как длины контекста достигают десятков и сотен тысяч токенов, кеш ключей и значений (key‑value cache) в декодерах трансформеров становится ключевым узким местом при развёртывании. Кеш хранит ключи и значения для каждого слоя и каждой головы в форме (2, L, H, T, D). Для эталонного трансформера, например Llama1‑65B, размер кеша достигает примерно 335 ГБ при 128 000 токенов в bfloat16, что ограничивает размер батча и увеличивает время до первого генерируемого токена.
В продуктивных решениях уже применяют сжатие кеша по разным осям. Grouped Query Attention делит ключи и значения между запросами и даёт коэффициенты сжатия по оси голов: примерно 4× в Llama3, 12× в GLM‑4.5 и до 16× в Qwen3‑235B‑A22B. DeepSeek V2 сжимает размерность ключей и значений через Multi‑head Latent Attention, а гибридные архитектуры комбинируют внимание со скользящим окном или слоями состояния для уменьшения числа слоёв, которые хранят полный кеш.
Однако эти приёмы не затрагивают ось последовательности: хотя разреженное или retrieval‑внимание извлекают лишь часть кеша на каждом шаге декодирования, все токены по‑прежнему занимают память. Для практической работы с длинными контекстами нужны методы, которые удаляют записи кеша, существенно не влияющие на будущую генерацию.
Проект KVpress объединяет более двадцати методов обрезки кеша в единой кодовой базе и предоставляет единые средства оценки нескольких подходов, включая H2O, Expected Attention, DuoAttention, Compactor и KVzip.
KVzip выступает сильным эталонным методом обрезки. Он вводит меру важности для каждой записи кеша через задачу «скопируй‑вставь»: модель заполняют расширённой подсказкой, где просят точно повторить исходный контекст, и для каждой позиции исходного контекста вычисляют максимальный вес внимания, который любая позиция в повторённом сегменте возвращает к этой позиции (с учётом группирования голов). Записи с низкой оценкой удаляются до достижения глобального бюджета.
Модификация KVzip+ уточняет эту оценку: она домножает вес внимания на норму вклада значения в residual‑стрим и нормализует по норме принимающего скрытого состояния. Это ближе отражает реальное изменение в residual‑пространстве и лучше коррелирует с итоговой точностью по сравнению с исходной метрикой.
Оба эти «оракульных» подхода эффективны, но затратны. KVzip требует предварительного заполнения расширённой подсказки, что удваивает длину контекста и делает метод слишком медленным для продакшена; кроме того, процедура оценки предполагает фиксированную подсказку и потому непригодна для выполнения во время пошагового декодирования.
KVzap предлагает обходной путь: вместо дорогостоящей оракульной оценки он обучает небольшой суррогатный модель‑модуль, работающий непосредственно на скрытых состояниях. Для каждого слоя и каждой позиции t модуль получает скрытый вектор h_t и прогнозирует логарифмические оценки важности для всех ключ‑значение голов.
Рассматриваются две архитектуры суррогата: один линейный слой (KVzap Linear) и двухслойный MLP с активацией GELU и шириной скрытого слоя, равной одной восьмой размерности скрытого состояния модели (KVzap MLP). Обучение проводится на выборке из предобучающих подсказок Nemotron: отфильтровано 27 тыс. подсказок длиной 750–1250 токенов, затем выбирается до 500 подсказок в подмножестве и по 500 позиций токенов в каждой подсказке.
Для каждой головы получается около 1.2 млн пар для обучения и примерно 23 тыс. пар валидации. Суррогат учится аппроксимировать логарифм оценки KVzip+, и по всем моделям коэффициент детерминации (квадрат Пирсона) между предсказаниями и оракулом достигает примерно 0.63–0.77; вариант с MLP последовательно превосходит линейный.
Во время инференса KVzap обрабатывает скрытые состояния и выдаёт оценки для каждой записи кеша; записи с оценкой ниже заданного порога отбрасываются, а скользящее окно из последних 128 токенов всегда сохраняется. В экспериментальной реализации обрезка выполняется после операции внимания.
KVzap использует пороговую отбраковку, а не жёсткий выбор top‑k: один и тот же порог даёт разные эффективные коэффициенты сжатия на разных наборах задач и даже для разных подсказок в пределах одного набора. Авторы отмечают до 20% вариации сжатия между подсказками при фиксированном пороге, что отражает различную плотность информации.
Накладные расходы по вычислениям невелики: в анализе на уровне слоя дополнительная стоимость KVzap MLP не превышает примерно 1.1% от FLOP‑ов линейных проекций, а линейный вариант добавляет около 0.02%. Памятные накладные расходы следуют тем же числам. В режимах с длинным контекстом квадратичная стоимость внимания доминирует, поэтому эти дополнительные FLOP‑ы практически незаметны.
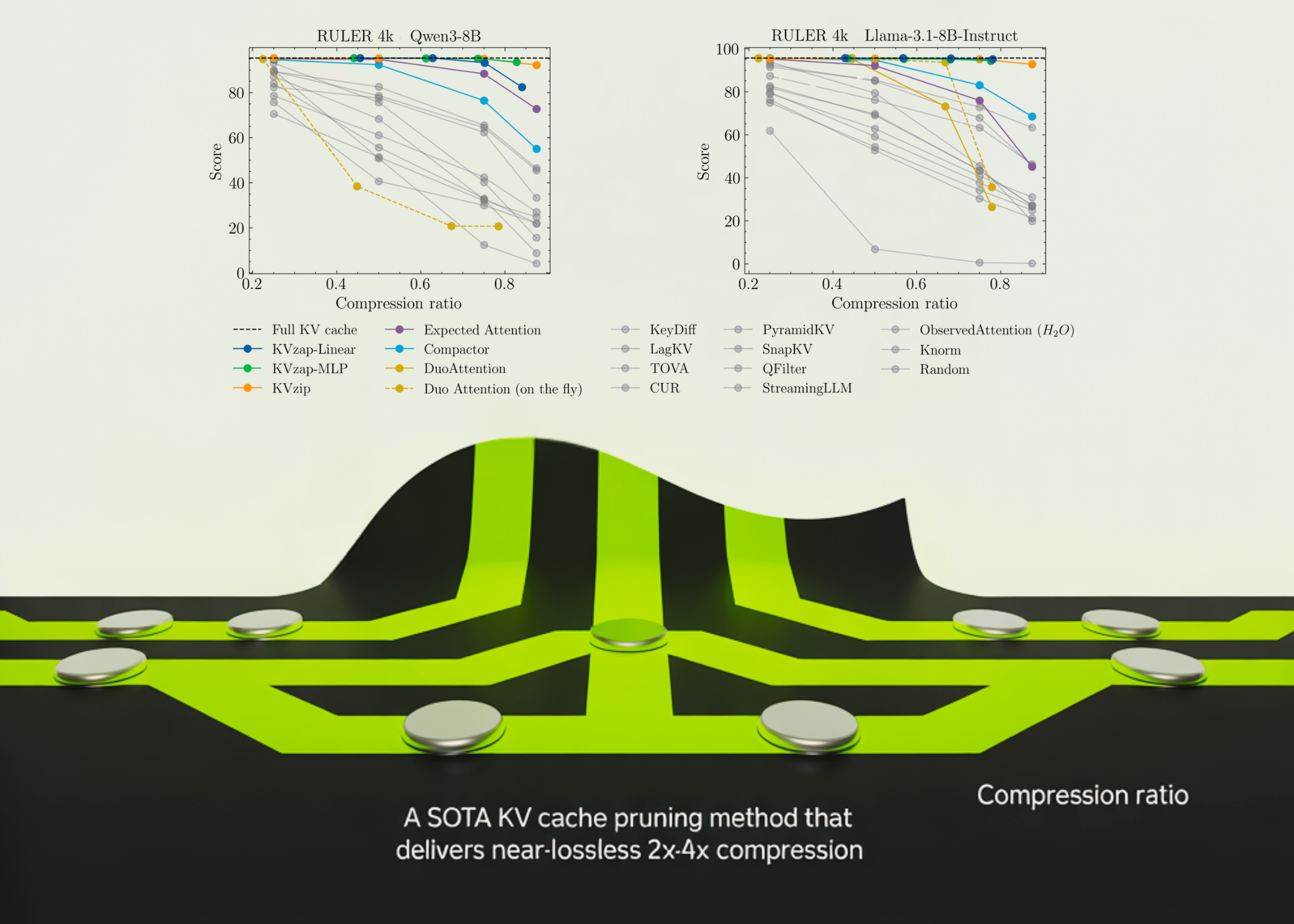
Оценка проводилась на длинных контекстах и задачах рассуждения с использованием Qwen3‑8B, Llama‑3.1‑8B Instruct и Qwen3‑32B. Поведение в длинном контексте измеряли на синтетическом наборе RULER (последовательности от 4k до 128k токенов) и на наборе реальных документов LongBench. Для задач математического рассуждения использовали набор AIME25 с 30 олимпиадными задачами, оцениваемыми по pass@1 и pass@4.
На RULER KVzap приближается к базовому варианту с полным кешем при удалении большой доли записей: для Qwen3‑8B лучшая конфигурация удаляла более 70% кеша на RULER 4k и 16k, сохраняя средний результат в пределах нескольких десятых пункта от полного кеша. Аналогичная картина наблюдалась и для других моделей.
На LongBench те же пороги дают более низкие коэффициенты сжатия из‑за меньшей повторяемости документов; KVzap остаётся близким к базовой модели до порядка 2–3× сжатия, тогда как методы с фиксированным бюджетом хуже деградируют при увеличении сжатия.
В AIME25 вариант KVzap MLP сохраняет или незначительно улучшает pass@4 при сжатии около 2× и остаётся работоспособным при удалении более половины кеша. Экстремальные настройки — например линейный суррогат при высоких порогах, удаляющих свыше 90% — ожидаемо приводят к резкому ухудшению качества.
В сумме лучшие конфигурации KVzap для разных моделей дают среднее сжатие кеша примерно в диапазоне 2.7–3.5× при сохранении качества задач очень близким к варианту с полным кешем на RULER, LongBench и AIME25.
Ключевые выводы: KVzap представляет собой адаптивную к входу аппроксимацию KVzip+, которая предсказывает важность пар ключ‑значение по скрытым состояниям с помощью небольших суррогатных моделей на каждом слое и отбрасывает пары с низкими оценками. Обучение проводится с супервизией от KVzip+ и даёт достаточно высокую корреляцию для корректной ранжировки важности.
Механика с пороговой отбраковкой плюс сохранение скользящего окна делает сжатие адаптивным к информационной плотности подсказок, а дополнительные вычисления и память малы, что делает метод практичным для интеграции в существующие стеки обслуживания длинных контекстов. KVzap реализован в открытом фреймворке kvpress и доступен с готовыми контрольными точками для дальнейшего использования.









Комментариев