Сегодня представляем Gemini 2.5 Flash Image, также известную как nano-banana — современную модель для генерации и редактирования изображений. Она позволяет объединять несколько изображений в одно, сохранять визуальную согласованность персонажей при последовательных правках и выполнять точечные трансформации с помощью естественных текстовых подсказок. Модель использует накопленные у Gemini знания о мире для более осмысленной генерации и редактирования изображений.
Ранее в этом году в Gemini 2.0 Flash была введена нативная генерация изображений, за которую пользователи отмечали низкую задержку, экономичность и простоту использования. При этом поступали запросы на более высокое качество итоговых изображений и расширённые творческие возможности. Gemini 2.5 Flash Image разработана с учётом этих отзывов.
Модель доступна сейчас через Gemini API, Google AI Studio и Vertex AI для корпоративных клиентов. Стоимость составляет 30 долларов за 1 миллион выходных токенов; каждое изображение занимает 1290 выходных токенов, что эквивалентно примерно 0,039 доллара за изображение. Для остальных входных и выходных модальностей применяется ценовая политика Gemini 2.5 Flash.
Мы обновили «режим сборки» в Google AI Studio, чтобы упростить создание приложений на базе модели. Встроенные шаблоны позволяют быстро оценить возможности, изменить их под свои задачи и запустить приложение напрямую из среды или сохранить код для дальнейшей разработки. Некоторые шаблоны доступны для использования и настройки бесплатно.
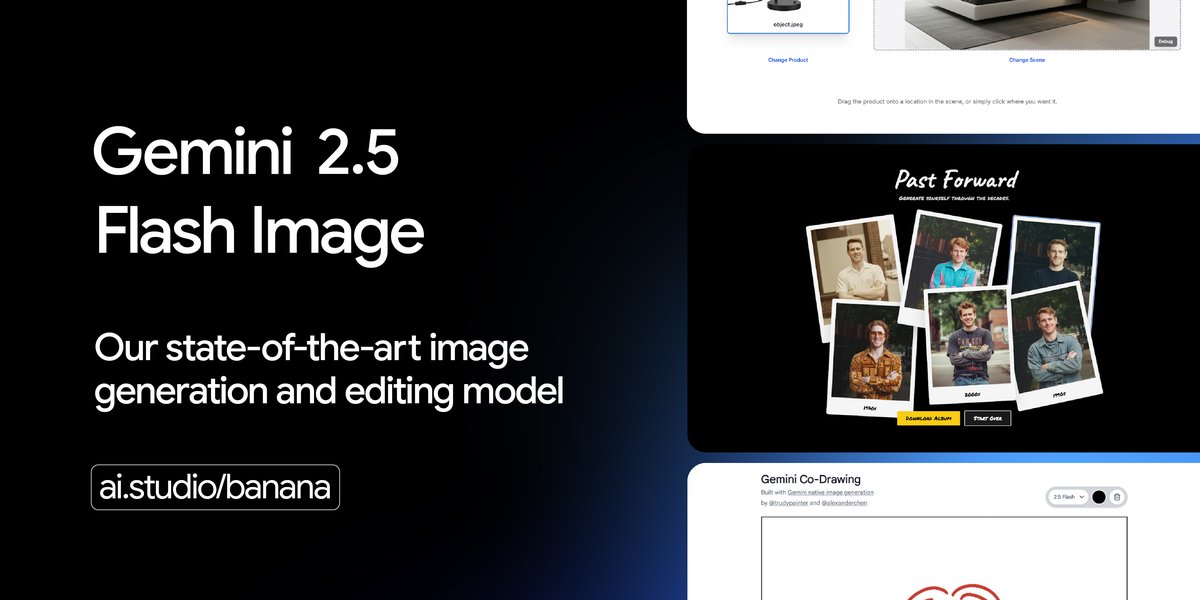
Одной из ключевых задач в генерации изображений является сохранение внешности персонажа или объекта при множественных запросах и правках. Gemini 2.5 Flash Image даёт возможность помещать одного и того же персонажа в разные окружения, демонстрировать товар с нескольких ракурсов и создавать согласованные бренд‑элементы без потери исходного образа. Для демонстрации этой возможности подготовлен шаблон в Google AI Studio.
Модель поддерживает точечное редактирование изображений на основе текстовых подсказок. Например, она может размыть фон, удалить пятно на одежде, убрать человека с фотографии, изменить позу субъекта или раскрасить чёрно‑белое фото по заданию пользователя. Для таких сценариев также создан шаблон приложения с интерфейсом и управлением через подсказки.
Gemini 2.5 Flash Image получила встроенное семантическое понимание реального мира, что открывает новые практические сценарии применения. Это позволяет распознавать и интерпретировать рукописные диаграммы, помогать с вопросами, связанными с реальными объектами, и выполнять сложные инструкции по редактированию за один шаг. В демонстрации шаблон превращает холст в интерактивного образовательного помощника.
Модель умеет объединять несколько входных изображений в одно аккуратно скомпонованное изображение. Благодаря этому можно вставлять объекты в сцены, изменять стиль интерьера по заданной палитре или текстуре и получать фотореалистичные результаты из разных источников. В демонстрациях показан инструмент, в котором товары можно перетаскивать в новую сцену для быстрой генерации композиций.
Для разработчиков доступны документация и примеры кода, облегчающие интеграцию модели в приложения. На данный момент модель доступна в режиме превью и в ближайшие недели планируется её перевод в стабильную версию. Партнёры, в том числе OpenRouter и fal.ai, помогают расширить доступность модели среди разработчиков.
Все изображения, созданные или отредактированные с помощью Gemini 2.5 Flash Image, будут содержать невидимый цифровой водяной знак SynthID, позволяющий идентифицировать их как сгенерированные или отредактированные ИИ. Мы продолжаем работу над улучшением рендеринга длинного текста, ещё более надёжной согласованности персонажей и точности воспроизведения деталей. Ждём отзывов и с интересом ожидаем, какие решения разработчики создадут с помощью Gemini 2.5 Flash Image.









Комментариев