NVIDIA объявила о расширении стратегического сотрудничества с Mistral AI и одновременном выпуске семейства открытых моделей Mistral 3. Партнёрство объединяет аппаратное ускорение и открытую архитектуру моделей, что, по заявлениям компаний, пересматривает эталонные показатели производительности.
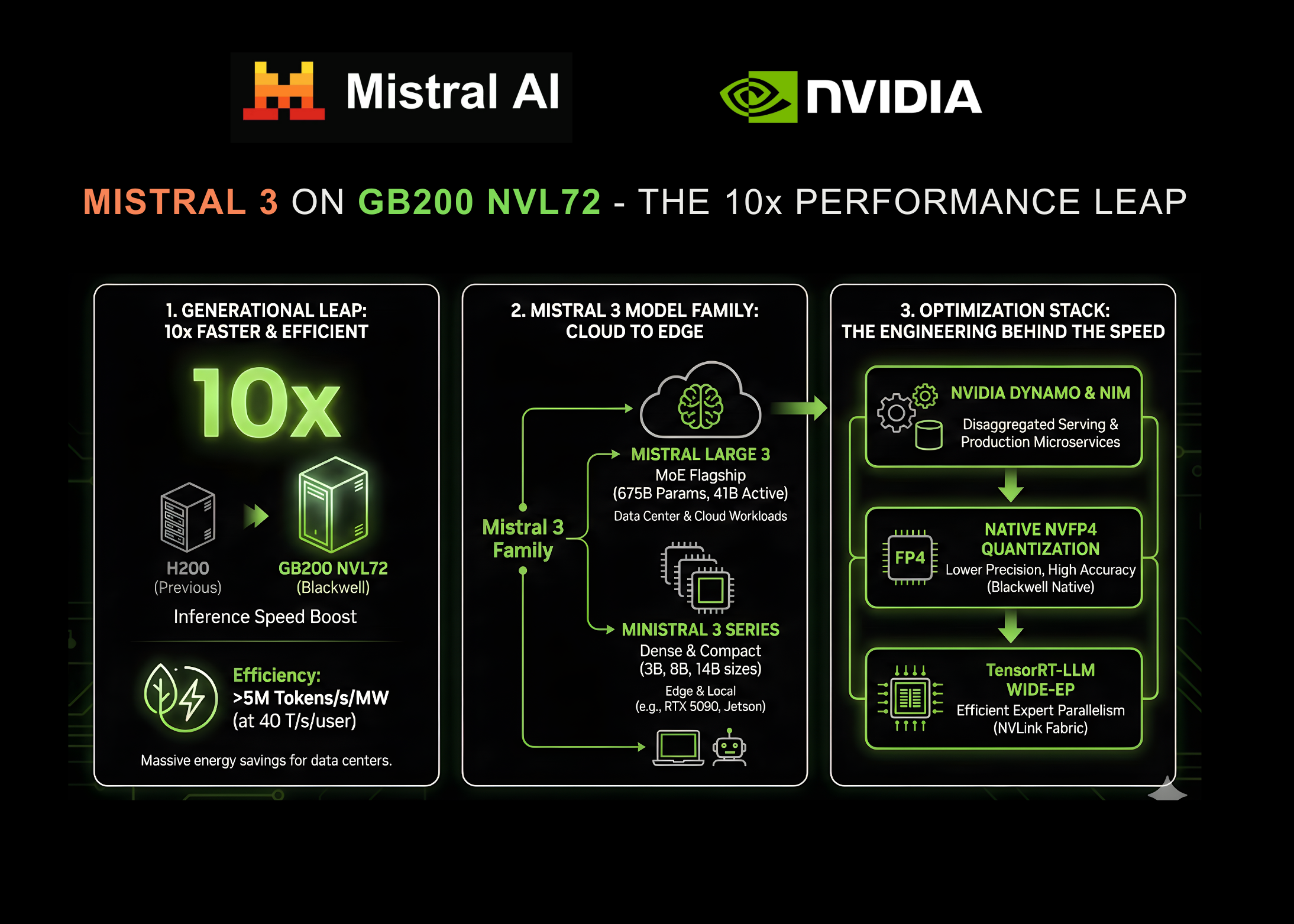
Новые модели демонстрируют значительный прирост скорости вывода: до десятикратного ускорения на системах NVIDIA GB200 NVL72 по сравнению с предыдущим поколением H200. Это улучшение позволяет повысить эффективность корпоративных решений ИИ и уменьшить задержки и затраты при масштабном развертывании моделей рассуждения.
По мере перехода спроса предприятий от простых чат-ботов к агентам с долгим контекстом и сложным рассуждением, эффективность вывода стала ключевым узким местом. Совместная работа NVIDIA и Mistral AI была направлена на оптимизацию семейства Mistral 3 под архитектуру Blackwell.
Система GB200 NVL72 обеспечивает до 10-кратного роста производительности по сравнению с H200 и одновременно повышает энергетическую эффективность. При интерактивных нагрузках около 40 токенов в секунду система, по данным компаний, превосходит 5 000 000 токенов в секунду на мегаватт потребляемой мощности.
Для дата-центров с ограничениями по энергопотреблению такой рост эффективности важен не менее, чем чистая скорость. Переход на новое поколение аппаратного и программного стека снижает стоимость обработки одного токена и сохраняет высокий пропускной потенциал для приложений реального времени.
Двигателем этих улучшений стало семейство моделей Mistral 3, которое сочетает высокую точность, эффективность и возможности кастомизации. Набор охватывает сценарии от крупных нагрузок в дата-центрах до вывода на периферийных устройствах.
Флагманом линейки является Mistral Large 3 — разреженная мультимодальная и многоязычная Mixture-of-Experts (MoE) модель. В общей сложности модель имеет около 675 миллиардов параметров, при этом активные параметры составляют примерно 41 миллиард, а контекстное окно достигает 256k токенов; обучение велось с использованием GPU архитектуры Hopper.
Ряд плотных моделей представлен под маркой Ministral 3 и ориентирован на скоростной и универсальный вывод. Серия включает варианты с примерно 3, 8 и 14 миллиардами параметров, каждый доступен в вариантах Base, Instruct и Reasoning (в сумме девять моделей), при этом у всех режимов одинаковое контекстное окно в 256k токенов.
По заявлению разработчиков, серия Ministral показывает высокие результаты на бенчмарке GPQA Diamond, достигая сопоставимой или лучшей точности при использовании примерно на 100 токенов меньше. Такая экономия токенов снижает вычислительные и временные издержки при работе в условиях ограниченного контекста.
Утверждение о десятикратном ускорении основано на стекe оптимизаций, совместно разработанном инженерами Mistral и NVIDIA. Подход «extreme co-design» сочетает аппаратные возможности Blackwell с изменениями в архитектуре и реализации моделей.
Одним из ключевых компонентов является TensorRT-LLM Wide Expert Parallelism (Wide-EP), позволяющий эффективно масштабировать MoE на GB200 NVL72. Wide-EP включает оптимизированные GroupGEMM-ядра, распределение экспертов и балансировку нагрузки, а также использует связность памяти и NVLink-фабрику для минимизации коммуникационных узких мест.
По данным разработчиков, Mistral Large 3 использует примерно 128 экспертов на слой, что примерно вдвое меньше, чем у ряда сопоставимых моделей, однако Wide-EP обеспечивает высокую пропускную способность и низкие задержки в распределённых конфигурациях. Это позволяет крупным MoE-моделям реализовать преимущества NVLink при сохранении масштабируемости.
Ещё одним значимым техрешением стала поддержка NVFP4 — нативного формата квантизации для архитектуры Blackwell. Для Mistral Large 3 предусмотрена возможность офлайн-квантизации контрольных точек в NVFP4 с использованием существующих инструментов с открытым исходным кодом.
Подход ориентирован на снижение вычислительных и памятьых расходов при минимальной потере точности, в том числе за счёт более точных масштабирующих факторов FP8 и более мелкомасштабного блочного масштабирования. Рецепты квантизации нацелены преимущественно на веса MoE, оставляя другие компоненты в исходной точности.
Для распределённого вывода используется фреймворк NVIDIA Dynamo, который разъединяет фазы prefill (обработка входного запроса) и decode (генерация вывода). Разделение и согласование скоростей выполнения этих фаз повышает пропускную способность при задачах с длинным контекстом, например конфигурациях 8k вход / 1k выход, и поддерживает эффективную работу с контекстным окном в 256k токенов.
Оптимизации распространяются и на периферию: серия Ministral 3 рассчитана на локальные и встроенные сценарии. Модели адаптированы для платформ типа настольных RTX и модулей NVIDIA Jetson, что даёт гибкость для разных применений.
На рабочей станции с GPU RTX 5090 варианты Ministral-3B, по оценкам разработчиков, способны достигать порядка 385 токенов в секунду, предоставляя класс производительности, пригодный для локальной разработки и повышающей конфиденциальность данных. Для робототехнических и встроенных систем на платформе Jetson Thor при использовании контейнера vLLM модель Ministral-3-3B-Instruct демонстрирует примерно 52 токена в секунду при одиночной конкуренции и до 273 токенов в секунду при конкуренции 8.
Проекты и интеграции поддерживаются в сообществе с целью широкого распространения: реализована совместимость с популярными фреймворками для локальной разработки и ускорения итераций, а также расширенная поддержка для спекулятивного декодирования и интеграции ядер под Blackwell.
Для упрощения внедрения в промышленную эксплуатацию модели будут доступны через микроcервисы NVIDIA NIM. Mistral Large 3 и некоторые варианты Ministral уже представлены в каталоге API и предварительных каналах доступа, а в будущем ожидается возможность загрузки контейнеризированных NIM-микросервисов для развёртывания на любой GPU-ускорённой инфраструктуре с минимальными доработками.
Такая доступность позволяет реализовать заявленное преимущество производительности GB200 NVL72 в продуктивных средах без сложной индивидуальной интеграции, что расширяет доступ к передовым решениям ИИ. Дополнительные оптимизации, включая спекулятивное декодирование с предсказанием нескольких токенов (MTP) и методы следующего поколения (например, EAGLE-3), могут ещё больше повысить показатели в будущем.
Разработчикам предлагается тестировать и бенчмарковать семейство Mistral 3 в публичных репозиториях моделей и на хостинговых платформах для оценки задержки и пропускной способности в конкретных сценариях. Это позволит оценить реальные выгоды от оптимизаций и выбрать подходящую конфигурацию для рабочих нагрузок.









Комментариев